
前言
分库分表是企业开发数据存储中非常常见的一项优化工作,但之前一直没有去认真了解过,直到最近接触了一个Spark表日同步千万数据到MySQL表的工作,才对分库分表有了一个初步的认识。
本文就是对这次分库分表初步学习的一个记录总结。
概述
在数据量较小的时候,数据多是以单表的形式存储。但随着业务量的扩大存储数据量的增加,单表的操作性能也会大大降低,影响正常的业务工作。
这时就需要考虑使用分库分表,一般而言,在单表数据量达到1000万左右(公司DBA建议)时,就可以考虑使用分库分表。
分库分表策略
¶垂直切分
用简单的话来说,垂直切分就是将一个表中涉及的多个字段切分到不同的表甚至是库中存储。如下图所示:
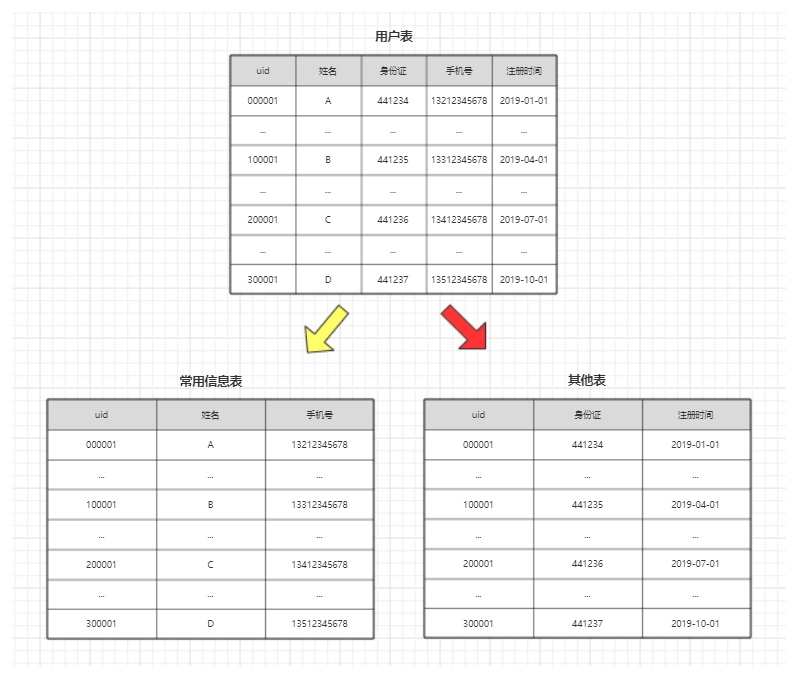
我们常用的 数据库三大范式 设计,其实也是一种垂直切分。
另一种常用的垂直切分,则是将热门访问字段与冷门访问字段进行切分,从而让数据库可以以更少的字段缓存更多的行,进而带来性能的提升。
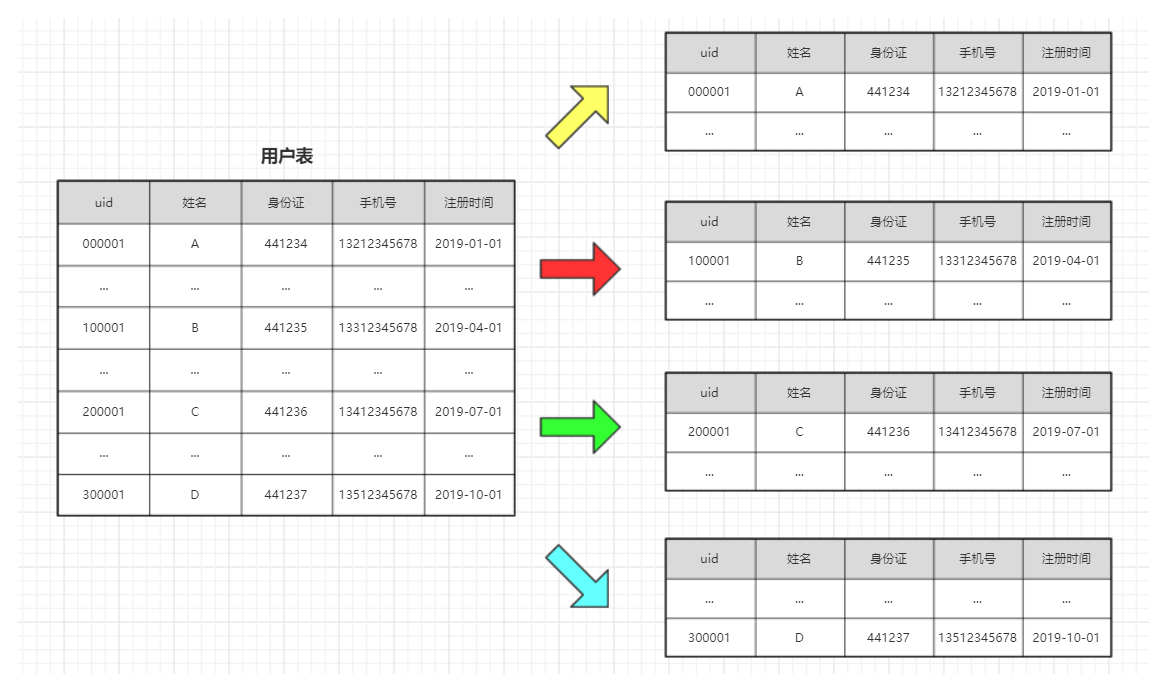
¶水平切分
用简单的话来说,水平切分就是将一个表中存储的数据依照某种策略存储到不同的表上。如下图所示:
¶Range
水平切分的第一种方式就是Range,即根据一定的范围进行分发。
如:根据时间范围,一个月的数据存储一张表,或者是根据用户ID这种自增序列,用户ID在000000至100000范围的存一张表,100001至200000范围的存一张表等。
根据Range分发的好处就是数据扩容时方便。缺点就是容易产生数据热点问题。
¶Hash
水平切分的第二种方式就是Hash,即通过一次哈希运算然后取余分表数量-1的方式确定数据要存的表的位置。
如:根据用户姓名进行Hash分发。用户姓名小明,计算hashcode,得到754703,预先确定分表数量为8,再取余7,得到3,即分发到索引为3的数据表上。
根据Hash分发的好处就是数据分发均匀,不会产生数据热点问题,但是扩容的时候非常不方便,还需要重新计算数据的哈希值。
MyBatis + ShardingJDBC 实践分库分表
ShardingJDBC是ShardingSphere的子项目,在Java的JDBC层提供的额外服务。具体可见ShardingPhere官方文档。
¶数据库准备
现有用户信息需要存储,分别有五个字段:uid、name、mobile、credit_id、create_time。
现在的分库分表策略是:
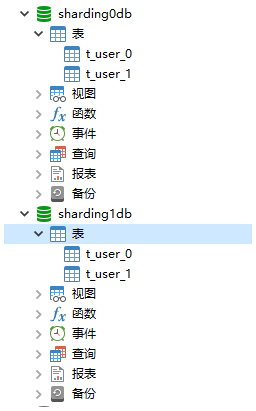
- 根据uid进行水平切分,uid最后一位为偶数的,分到sharding0db数据库,否则分到sharding1db数据库。
- 在各数据库中,uid倒数第二位为偶数的,分到t_user_0表,否则分到t_user_1表。
所以每个表存储的字段都是一样的,其中一个表的数据库 Schema 脚本如下:
1 | DROP TABLE IF EXISTS `t_user_0`; |
在sharding0db与sharding1db都建立了数据表后,结构如下图所示:
¶Maven依赖
本项目使用的是Spring-Boot 2.0.3.RELEASE,在项目中导入以下Maven依赖:
1 | <dependencies> |
¶配置文件
在application.yml中进行配置:
1 | spring: |
¶编码
准备UserDAO文件:
1 |
|
准备UserDAO的XML映射:
1 |
|
准备User实体:
1 |
|
编写单元测试插入数据,这里是通过随机生成100个用户的uid进行测试:
1 | (SpringRunner.class) |
¶运行结果
查看数据结果,可以看到数据已成功插入到指定的数据库表中。
最后一位为奇数,倒数第二位为偶数的,被插入到sharding1db.t_user_0:
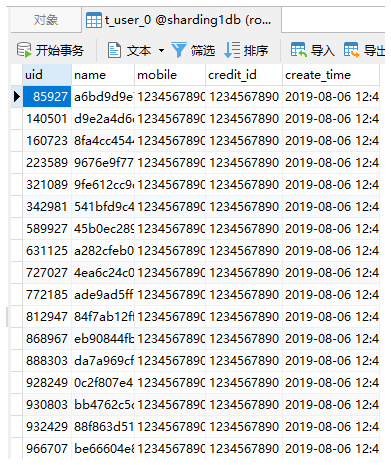
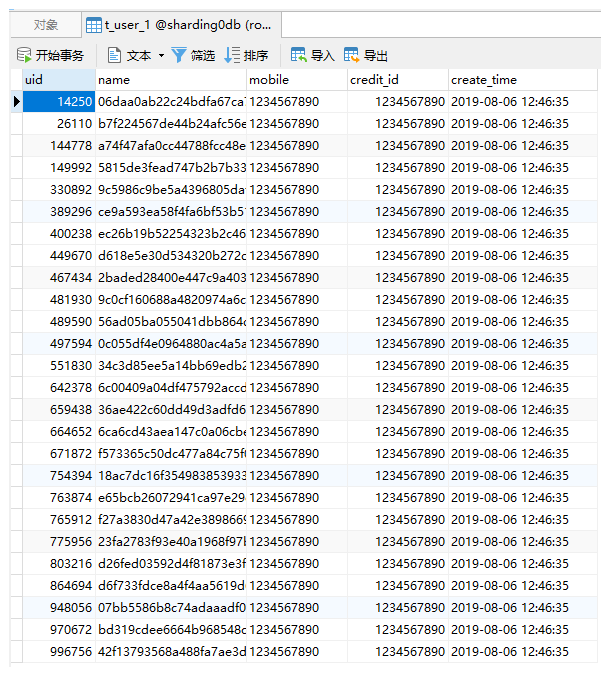
最后一位为偶数,倒数第二位为奇数的,被插入到sharding0db.t_user_1:
参考资料
| # | 文章链接 | 作者 |
|---|---|---|
| 1 | sharding:谁都能读懂的分库、分表、分区 | 骏马金龙 |
| 2 | 一次难得的分库分表实践 | crossoverjie |
| 3 | advanced-java | doocs |