
Guava概述
Guava是Google开源的一个Java库,Google最早提出它,是对Java Collection进行扩展以提高开发效率。随着时间推移,Guava已经覆盖到了Java开发的方方面面,包括提供用于集合,缓存,I/O,并发等。截止到28.0-jre版本,Guava的基本结构如图所示:
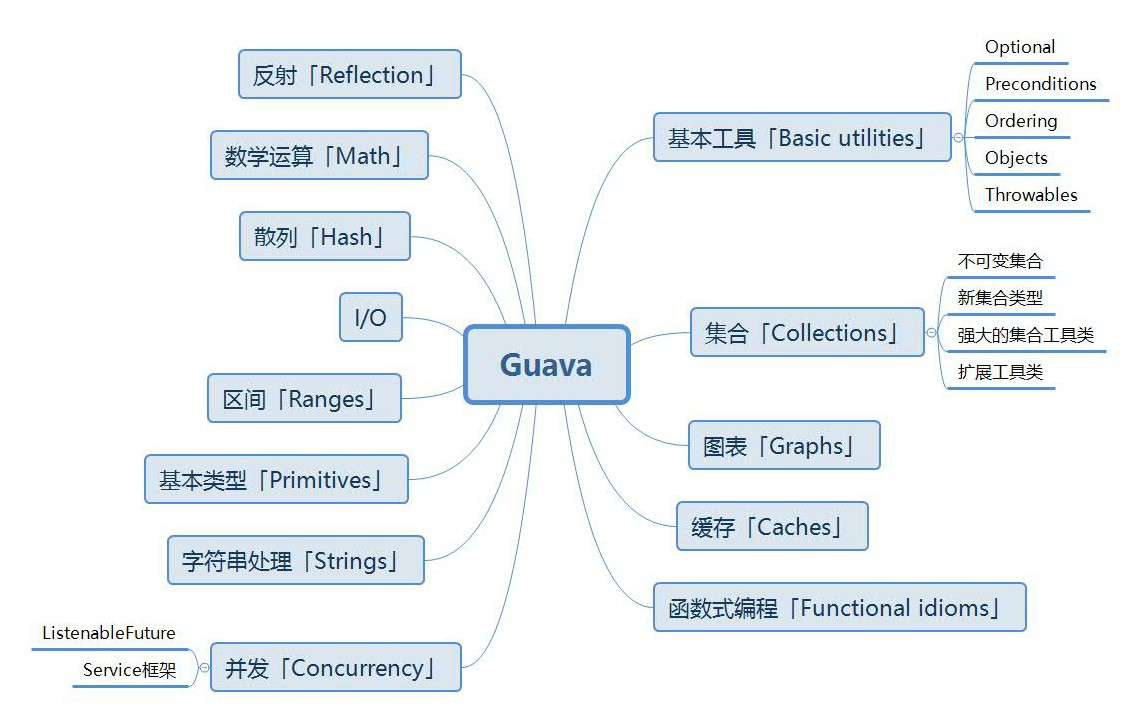
本笔记记录了个人的Guava学习重点总结,主要面向的Java版本是JDK1.7与JDK1.8,针对其他版本的特性暂不作记录,更多完整的内容可以参考Guava的中文指导、英文指导与Api文档。
1 基本工具「Basic utilities」
¶1.1 Optional
Guava用Optional<T>表示可能为null的T类型引用。一个Optional实例可能包含非null的引用(我们称之为引用存在),也可能什么也不包括(称之为引用缺失)。
使用Optional除了赋予null语义,增加了可读性,最大的优点在于它是一种傻瓜式的防护。Optional迫使你积极思考引用缺失的情况,因为你必须显式地从Optional获取引用。
¶Optional的常用Api
1 | /** |
在JDK1.8中已经提供了功能相同的java.util.Optional类。
¶1.2 Preconditions
前置条件:让方法调用的前置条件判断更简单。
¶Preconditions的常用Api
1 | /** |
¶1.3 Ordering
Ordering是Guava链式风格比较器Comparator的实现,它可以用来为构建复杂的比较器,以完成集合排序的功能。
从实现上说,Ordering实例就是一个特殊的Comparator实例。Ordering把很多基于Comparator的静态方法包装为自己的实例方法,并且提供了链式调用方法,来定制和增强现有的比较器。
¶Ordering的常用Api
1 | /** |
¶1.4 Objects
Objects与JDK1.7中提供的方法类似,不再赘述。
¶1.5 Throwables
Throwables与JDK1.7中提供的多重catch功能类似,不再赘述。
2 集合「Collections」
¶2.1 不可变集合
不可变集合因为不可变性,所以可以作为常量,且在被多个线程调用时,不存在竞态条件问题。
¶不可变集合的常用Api
1 | /** |
¶2.2 新集合类型
Guava引入了很多JDK没有但是非常有用的新集合类型。
¶2.2.1 Multiset
Multiset允许元素重复,元素之间没有顺序。
我们经常碰到一类统计需求——统计某个对象(常见的如字符串)在一个集合中的出现次数,使用JDK提供的数据结构,我们会这么做:
1 | Map<String, Integer> counts = new HashMap<String, Integer>(); |
Guava提供了一个新集合类型 Multiset,它可以多次添加相等的元素,使用Guava改进代码如下:
1 | Multiset<String> multiset = HashMultiset.create(); |
¶2.2.2 Multimap
Multimap可以把键映射到任意多个值上。
在JDK提供的集合元素中,我们经常会使用Map<K, List
1 | Multimap<String, Integer> multiMap = ArrayListMultimap.create(); |
¶2.2.3 Table
Table带有两个支持所有类型的键:”行”和”列”。
我们有时候会用到这样一种数据结构:Map<R, Map<C, V>>,在Guava中,可以使用Table来实现:
1 | Table<Integer, Integer, Double> weightedGraph = HashBasedTable.create(); |
其他更多新集合类型见Guava的中文指导:新集合类型。
¶2.3 集合扩展增强
Guava引入了很多JDK没有但是非常有用的新集合类型。
¶2.3.1 静态创建方法
通过使用Guava提供的静态创建方法,可以简化集合创建代码的编写。
在JDK提供的集合中,我们初始化一个集合,需要这么做:
1 | List<String> list = new ArrayList<>(); |
而在Guava中,可以轻松使用一行代码实现:
1 | List<String> list = Lists.newArrayList("a", "b", "c", "d"); |
同理,创建其他集合,也可以用这种方式实现。
¶2.3.2 集合工具类
Gauva提供了Lists、Sets、Maps、Multisets等工具类,方便对集合进行操作。
以下是常用Api示例:
1 | List countUp = Ints.asList(1, 2, 3, 4, 5); |
¶2.3.3 扩展工具类
让实现和扩展集合类变得更容易,比如创建Collection的装饰器,或实现迭代器。这一部分目前用的不是很多,暂时不作记录。
3 图表「Graphs」
用的不多,暂不记录。
4 缓存「Caches」
Guava提供本地缓存,本地缓存作用就是提高系统的运行速度,是一种空间换时间的取舍。它实质上是一个做key-value查询的字典,但是相对于常用的HashMap它又有以下的不同点:
- 并发性;由于目前的应用大都是多线程的,所以缓存需要支持并发的写入,这点在ConcurrentHashMap上一致的。
- 过期策略;在某些场景中,我们可能会希望缓存的数据有一定“保质期”,过期策略可以固定时间,例如缓存写入10分钟后过期。也可以是相对时间,例如10分钟内未访问则使缓存过期(类似于servlet中的session)。在java中甚至可以使用软引用,弱引用的过期策略。
- 淘汰策略;由于本地缓存是存放在内存中,我们往往需要设置一个容量上限和淘汰策略来防止出现内存溢出的情况。
Guava的Caches使用的是LRU(Least Recently Used)过期策略,即淘汰最后一次使用时间离当前最久的缓存数据,保留最近访问的数据。
¶4.1 缓存的创建
Cache与LoadingCache是Guava提供的两种构建本地缓存的方式。
¶4.1.1 Cache
Cache通过CacheBuilder的build()方法构建,当缓存不存在时,则通过Callable进行加载并返回,该操作是原子操作。
1 | Cache<String, String> cache = CacheBuilder.newBuilder() |
¶4.1.2 LoadingCache
LoadingCache通过CacheBuilder的build(CacheLoader<? super K1, V1> loader)方法构建:
1 | LoadingCache<String, String> loadingCache = CacheBuilder.newBuilder() |
¶4.2 缓存的参数设置
¶4.2.1 缓存的并发级别
设置并发级别,使得缓存支持并发的写入和读取。
1 | CacheBuilder.newBuilder() |
¶4.2.2 缓存的初始容量
设置一个合理大小初始容量,减少缓存的扩容次数。
1 | CacheBuilder.newBuilder() |
¶4.2.3 缓存的回收
制定缓存的回收策略,防止内存溢出。
基于数量回收:
1 | CacheBuilder.newBuilder() |
基于容量回收:
1 | CacheBuilder.newBuilder() |
基于引用回收:
1 | CacheBuilder.newBuilder() |
显示回收:
1 | // 构建一个缓存 |
¶4.2.4 缓存的过期策略
通过为缓存设置过期策略以为缓存数据提供保质期。
固定时间过期:
1 | CacheBuilder.newBuilder() |
相对时间过期:
1 | CacheBuilder.newBuilder() |
¶4.2.5 缓存的刷新
Guava目前支持的刷新方式包括定时刷新与显示刷新。
定时刷新:
1 | // 目前只有CacheLoader支持定时刷新 |
显示刷新:
1 | // 构建一个缓存 |
5 函数式编程「Functional idioms」
替换使用JDK1.8的Lambda表达式,暂不记录。
6 并发「Concurrency」
暂空。
7 字符串处理「Strings」
¶7.1 Joiner
Joiner用于简化字符串的连接工作。
1 | Joiner joiner = Joiner.on(",").skipNulls(); |
¶7.2 Splitter
1 | // 返回Harry,Ron,Hermione |
¶7.3 CharMatcher
CharMatcher是为了匹配与处理这些匹配的字符。
8 基本类型「Primitives」
Guava的Primitives提供了许多int、double等基本类型的工具类。
Primitives常用Api:
1 | // 返回[1, 2, 3, 4] |
9 区间「Ranges」
Guava提供的Ranges是一个可以比较类型的区间Api。
构建Ranges:
1 | // 返回(1, 5) |
Ranges常用Api:
1 | // 返回false,查询(4, 5]是否为空 |
10 I/O
JDK7开始已有提供功能类似的工具类,暂略。
11 哈希「Hash」
Guava的Hash是对JDK提供的Hash的增强,通常运用于简单散列表以外的散列运用。
构建HashCode:
1 | HashFunction hf = Hashing.md5(); |
布隆过滤器:
1 | class Person { |
12 事件总线「EventBus」
暂空。
13 数学运算「Math」
使用Guava的Math可以进行防溢出检测以及其余复杂运算。
常用Api:
1 | // 返回log以2为底的10的对数,第二个参数为RoundingMode舍入策略 |
具体可见:Guava-Math中文文档。
14 反射「Reflection」
暂空。